Pruebas de hipótesis como herramienta matemática clave para la estrategia basada en datos
¡Hola! ¡Bienvenidos a este artículo! Es la primera vez que escribo para Medium, algo que espero se convierta en una afición a la que me dedique más a menudo.
No soy escritor profesional, pero creo que me apasiona el tema que me interesa: aprender y enseñar a la gente las matemáticas necesarias para aplicarlas a sus negocios. Como empresario que luego se convirtió en científico de datos, me emociona cada vez que aprendo algo con lo que se pueden obtener ventajas competitivas injustas.
El tema de hoy gira en torno a lo que creo que es una de las habilidades clave que cualquier científico de datos o ingeniero matemático debería tener para enfocar sus talentos en la industria, y un elemento clave en la estrategia basada en datos.
Por si has ignorado el título y te gusta leer publicaciones aleatorias sin consultar primero sus títulos, me refiero a las pruebas y demostraciones de hipótesis. En esta publicación, antes de entrar en detalles técnicos y explicar matemáticamente su funcionamiento, intentaré convencerte de por qué esta herramienta es fundamental para la estrategia empresarial y darte una idea de cómo funciona.
¿Por qué es tan importante?

Tomé esa foto de una flor con mi camara, también hago fotos guays! :D
Razón 1: Reducir el riesgo en la toma de decisiones
Bueno, esta es fácil de responder. Probablemente hayas notado cómo el término “basado en datos” se ha vuelto cada vez más popular recientemente. Su popularidad no es infundada: ha habido un cambio de paradigma total en la forma en que se elaboran y deciden las estrategias empresariales y el emprendimiento durante los últimos 20 años (básicamente porque los pioneros en hacerlo conquistaron el mundo y ahora se han convertido en reyes tecnológicos con FAANGs muy agudos). La clave de su éxito reside en que la estrategia ahora se basa en datos.
Ahora las decisiones se toman no solo con base en la intuición, un liderazgo carismático y la confianza en el análisis heurístico de mercado basado en la experiencia, sino también con un conocimiento equivalente al hecho científico de que esos líderes probablemente aciertan, con cierto grado de confianza en las ideas por las que apuestan.
Puedes imaginar las diferencias de éxito entre una empresa que toma una decisión y cree tener razón, pero no está realmente segura, y las que la toman con una sólida base de experimentos y pruebas que indican que probablemente aciertan con un 95% de confianza. La supervivencia del más apto, como decía Darwin, es fundamental para estar en forma en la jungla empresarial actual: una estrategia basada en datos. No existe una estrategia basada en datos si no podemos demostrar, o al menos reducir, la probabilidad de que las suposiciones en las que se basan esas decisiones sean erróneas. Las pruebas de hipótesis, como su nombre indica, ayudan precisamente con esto.
En teoría, cualquier decisión que una empresa afronte (que tenga implicaciones directas en su éxito o fracaso en el mercado competitivo) se basa en una hipótesis (creencias) sobre el funcionamiento de ese mercado o situación, lo que la convierte en una habilidad esencial para implementar una estrategia basada en datos/hechos.

Imagen libre de derechos de autor de personas decidiendo cosas, porque no quiero que tus ojos se cansen de leer demasiado.
Razón 2: Mantener y potenciar la ingeniería matemática en la empresa
Existe también un segundo uso muy importante para las pruebas de hipótesis en los negocios, que muchos pasan por alto. Las pruebas de hipótesis son también una herramienta fundamental para el correcto mantenimiento y la monitorización de la IA y las soluciones matemáticas que tienen el potencial de aportar valor, basándose en datos.
Todos los casos de uso empresarial dependen de un análisis estadístico de las realidades empresariales (en forma de variables), las cuales están sujetas a distribuciones estadísticas específicas que afectan directamente el impacto de dichas variables en el problema en cuestión. Normalmente, para construir y utilizar una herramienta matemática, ya sea un algoritmo de aprendizaje automático u otro, se proporcionan ejemplos históricos de esa realidad empresarial para enseñar o comprender sus propiedades estadísticas.
Con este conocimiento, la herramienta puede mapear su comportamiento y utilizarlo para una solución específica. Predicción, recomendación, clasificación, análisis de insights, sea lo que sea, la solución utiliza datos históricos para comprender matemáticamente el problema empresarial y, a través de esa comprensión, puede aportar valor en forma de insights y un conocimiento más profundo que la heurística basada en la experiencia no puede alcanzar por sí sola. La cuestión es que, a menudo, los problemas empresariales no son sistemas estáticos, sino dinámicos y caóticos, altamente dependientes de la participación de las entidades sociales (comúnmente conocidas como partes interesadas). Estas entidades evolucionan, cambian y se adaptan, y por lo tanto, las distribuciones estadísticas derivadas de su observación podrían cambiar con ellas.
Esto significa que, con el tiempo, podría llegar el día en que las propiedades estadísticas de una realidad (variable) particular difieran de las que la herramienta aprendió con los datos originales. Si esto ocurre, la herramienta se vuelve obsoleta, y todo el arduo trabajo de desarrollo, I+D, estudio y producción de la solución matemática puede desperdiciarse, y lo que es peor, sin que la empresa lo note. Simplemente verán que la herramienta no está dando buenos resultados por alguna razón.
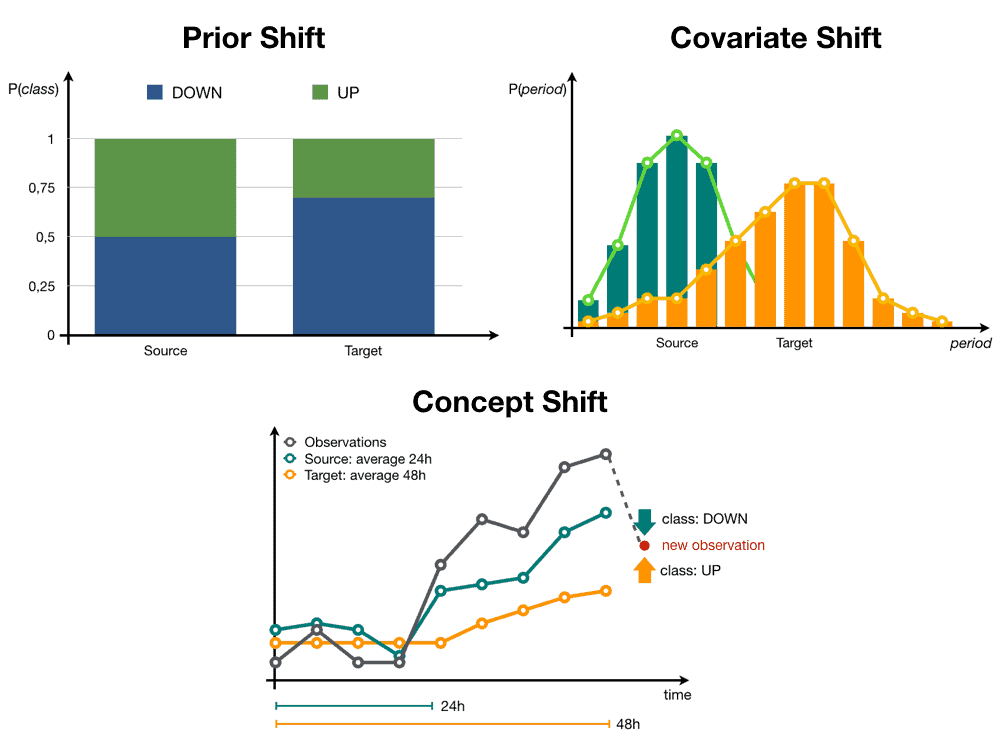
Las pruebas de hipótesis permiten medir con precisión este proceso. Puede demostrar la hipótesis de que las propiedades estadísticas (generalmente la distribución de probabilidad) de los datos utilizados originalmente para entrenar su herramienta matemática son las mismas que las de ejemplos de datos nuevos y recientes, y preparar protocolos de reentrenamiento o modificación de la solución con base en los resultados de dichas pruebas. Esto se conoce como análisis de deriva de datos y monitoreo de la calidad de los datos, y es un campo de estudio importante en la ingeniería matemática.

Imagen de diferentes técnicas de análisis de deriva de datos del blog de dataiku: un lugar donde ponen mucho más esfuerzo en su blog que yo para crear sus propias imágenes, y que definitivamente deberías leer.
Esto convierte la prueba de hipótesis en un elemento clave no solo para la toma de decisiones, sino también para cualquier solución matemática basada en datos en la empresa, y resolver problemas con matemáticas es una gran ventaja.
¿Cómo funcionan realmente las pruebas de hipótesis? Comprendiendo la reducción de riesgos con un ejemplo: El caso del vino de las amas de casa desesperadas
La prueba de hipótesis suele consistir en demostrar que dos variables diferentes tienen distribuciones estadísticas iguales o diferentes. Esto se realiza comparando propiedades específicas de sus distribuciones, por ejemplo, su media y la frecuencia de sus valores esperados, entre otras, y midiendo mediante un experimento si presentan valores que serían muy improbables si no fueran diferentes.

Imagen de este fantástico blog vzhorui.net, bastante avanzado e interesante también.
En esencia, se trata de demostrar que una variable específica de la realidad empresarial que nos interesa se transforma en una distribución completamente diferente después de que la empresa implemente algo (generalmente estratégicamente planificado) para afectarla. Este “algo” es lo que en matemáticas causales llamamos “tratamiento” (si esto les recuerda a la medicina, es porque es la esencia de cómo se realiza la investigación médica).
Por ejemplo, imaginemos que tenemos una variable llamada “X” que representa las ventas de un segmento específico de clientes, por ejemplo, amas de casa desesperadas de 40 años, para un producto específico de nuestra empresa dirigido a ese público, tal vez el servicio de catering de vinos. Queremos demostrar que nuestro tratamiento, una campaña de marketing por correo electrónico específica, es eficaz para que las amas de casa desesperadas intenten comprar nuestro servicio.
Para ello, lo que haríamos básicamente sería recopilar datos (por ejemplo, datos web) de las ventas de ese producto, durante un período de tiempo, quizás un mes, sin aplicar el tratamiento, y otro período de tiempo donde sí se aplica el tratamiento. Tendríamos una muestra de la variable, antes y después del tratamiento, y sólo necesitaríamos demostrar mediante pruebas de hipótesis si son parte de la misma distribución o no.

clip de la serie desperate housewives bebiendo vino.
O quizás, otro experimento que podríamos hacer es simplemente comparar las conversiones de las amas de casa a las que no enviamos ningún correo electrónico (pero que, de alguna manera, conseguimos que llegaran durante el resto del proceso de marketing) con las de aquellas a las que sí les enviamos un correo electrónico. Esto se conoce comúnmente como prueba A/B. Compararíamos las distribuciones de dichas conversiones y, si se demuestra la hipótesis de que son diferentes, podemos confiar en la hipótesis de que el tratamiento, el correo electrónico, tiene un impacto en las ventas.
Nota importante: Las pruebas A/B son preferibles y más sólidas científicamente que comparar conjuntos de datos en diferentes períodos de tiempo, ya que hay mucha menos probabilidad de que existan variables de confusión (causas desconocidas que generan diferencias entre distribuciones, por ejemplo, debido a cambios de mercado no monitorizados) que influyan en el resultado de la prueba. Por lo tanto, se deben tomar más precauciones si se utiliza una alternativa a la prueba A/B.
Utilizo dos ejemplos clásicos de cómo se realizan este tipo de pruebas y, a propósito, hablo de la más popular en la estrategia basada en datos: la prueba A/B. No voy a entrar en detalles sobre cómo realizar estas pruebas (esto sería una publicación bastante larga, y ya lo es). Sin embargo, les diré algo que mucha gente parece olvidar:
Ejemplo aplicado a las pruebas de hipótesis para la generación de conocimiento
Hay mucho más que hacer con las pruebas A/B para demostrar hipótesis, y mucho más que centrarse únicamente en el impacto de una herramienta, solución o campaña específica, un “tratamiento” real.
Podemos usar las pruebas de hipótesis, por ejemplo, para demostrar nuestro conocimiento sobre un área de negocio o un problema en particular. En estos casos, el tratamiento es simplemente una característica que hemos monitoreado y observado.
Por ejemplo, imaginemos que tenemos un conjunto de datos completo con las características del comprador. Quizás, cuando las amas de casa desesperadas acuden al catering, las entrevistamos y almacenamos la información en un CRM.
Imaginemos que tenemos la hipótesis de que tal vez podría ser una idea clave para dirigirnos a ese público: creemos que, muy probablemente, las amas de casa desesperadas que contratan nuestros servicios son más propensas a comprar si están deprimidas, y creemos que una buena métrica proxy para evaluar la depresión es analizar si una persona se ha divorciado más de tres veces. No se trata de un tratamiento específico que queremos demostrar, sino de una característica que consideramos importante y simplemente queremos demostrar sin lugar a dudas que esto sucede. Podríamos recopilar los datos de nuestro CRM y comparar las distribuciones estadísticas de los clientes con 3 o menos divorcios y los clientes con más de 3, por ejemplo. En este caso, el “tratamiento” es el “número de divorcios” característico. Realizaríamos una prueba de hipótesis exactamente de la misma manera y obtendríamos información clave sobre nuestra audiencia.
Poco a poco, podríamos crear un mapa de las características y motivaciones de los clientes, basado en un proceso de entrevistas cualitativas y demostrado mediante análisis estadístico. Esto nos ayudaría enormemente a tomar decisiones que, sin duda, aumentarían las ventas. Finalmente, podríamos incluso tener un mapa del problema como este:

Diagrama de bucle causal real que analiza las causas del consumo excesivo de alcohol, obtenido a partir de este super cool paper Creado por Ivana Stankov, Yong Yang y compañía. Todas las empresas deberían aspirar a crear este tipo de gráficos para problemas específicos que puedan ayudarles a vender más, y las pruebas de hipótesis pueden utilizarse para ello.
Esto también se puede aplicar al proceso de fabricación, las finanzas, la contratación y a todas las áreas de la empresa. Todas las áreas tienen métricas que podemos “tratar” para mejorar, y características de las que podemos aprender para mejorar tratamientos posteriores.
Espero que ya haya quedado claro cómo las pruebas de hipótesis afectan directamente a la toma de decisiones. Imaginen poder mapear partes de la empresa en la que trabajan con un mapa sólido y científicamente probado como el que se mostró anteriormente. La ventaja de tener ese conocimiento es incalculable.
Veamos ahora cómo afecta a la implementación de servicios basados en matemáticas en la empresa:
Ejemplo aplicado al mantenimiento de ingeniería matemática.
Este es aún más fácil de explicar; sigamos con nuestro ejemplo.
Imaginen que, gracias a nuestra genial y única idea, decidimos dar luz verde a un sistema de recomendaciones que, basándose en una gran cantidad de datos sobre las características de las amas de casa, entregará vinos específicos al servicio de catering al que se suscriban.
Tras meses de desarrollo, el sistema está en producción, ¡y nuestros índices de aprobación y satisfacción con el servicio de catering se disparan! Originalmente, nuestro público objetivo era, por ejemplo (un ejemplo muy reduccionista y simple), el 50% de amas de casa divorciadas. Al ser un sistema muy costoso de capacitar, solo lo capacitamos cada seis meses. Quizás pasen seis meses y ocurra algo terrible, como una pandemia, que dispare las tasas de divorcio a un ritmo nunca visto ni detectado.
¿De repente, nuestro servicio de catering parece no recibir tan buenas recomendaciones como antes? ¿Qué sucedió?
Nuestro equipo de investigación de clientes, tras realizar varias rondas de entrevistas, tiene una hipótesis:
Antes teníamos una buena representación de amas de casa solteras, pero ahora el porcentaje de divorciadas es mucho mayor, lo que las lleva a hablar más en grupos de Reddit y Facebook, con conocimientos más específicos y seleccionados, generando así una diferencia en sus intereses.

Otra imagen divertida y libre de regalías para que no se te canse la vista, ¡esta vez sobre gente haciendo un focus group! Porque estábamos hablando de eso, ¿lo pillas? ¡Jaja!
Los datos originales con los que entrenamos nuestro sistema de recomendaciones presentan una distribución de las características diferente a la que observamos actualmente.
El entrenamiento original del sistema está obsoleto y sus gustos e intereses han cambiado. (Este tipo de evolución caótica es común en sistemas dinámicos donde los clientes intervienen; son sistemas muy caóticos que pueden viralizar las acciones o cancelarlas a un ritmo muy irregular).
Con las pruebas de hipótesis, habríamos detectado inmediatamente (aunque no supiéramos qué estaba sucediendo) que el conjunto de entrenamiento que usamos hace seis meses tenía distribuciones de características completamente diferentes a las de los conjuntos de datos que alimentamos diariamente al sistema. Habríamos detectado el riesgo de desviación de datos y decidido volver a entrenar el modelo. Aunque desconocemos cómo afectará el cambio de distribución a los intereses de los clientes, ya nos estamos preparando para ello, sabiendo que el cambio ya se ha producido y que debemos estar atentos (quizás esto dé lugar a rondas de entrevistas antes de observar una disminución en las métricas).
Así es exactamente como se utilizan las pruebas de hipótesis para mantener, controlar la calidad y reducir los costes de formación de los sistemas matemáticos que dependen de los datos de la empresa. También para supervisar los gráficos de conocimiento dentro de las empresas y decidir cuándo se necesita más investigación de clientes.
En resumen, espero que ya haya quedado clara la importancia de las pruebas de hipótesis para una estrategia basada en datos. Fue una publicación muy práctica y sin tecnicismos. Si quieres ver más detalles sobre cómo se realizan los experimentos reales (y cómo se aplican realmente las pruebas de hipótesis), estate atento a las próximas publicaciones sobre el tema.